
Scene reconstruction from multi-view images is a fundamental problem in computer vision and graphics. Recent neural implicit surface reconstruction methods have achieved high-quality results; however, editing and manipulating the 3D geometry of reconstructed scenes remains challenging due to the absence of naturally decomposed object entities and complex object/background compositions. In this paper, we present Total-Decom, a novel method for decomposed 3D reconstruction with minimal human interaction. Our approach seamlessly integrates the Segment Anything Model (SAM) with hybrid implicit-explicit neural surface representations and a mesh-based region-growing technique for accurate 3D object decomposition. Total-Decom requires minimal human annotations while providing users with real-time control over the granularity and quality of decomposition. We extensively evaluate our method on benchmark datasets and demonstrate its potential for downstream applications, such as animation and scene editing.

We utilize the MonoSDF for implicit neural surface reconstruction, augment it with a feature rendering head, and distill features from the above 2D backbones. The rendered features after distillation are depicted in the above figure. We observe that: (1) distilled CLIP-LSeg features cannot distinguish objects of the same categories; (2) distilled DINO features lack accurate object boundaries; and (3) distilled SAM features preserve object boundaries.
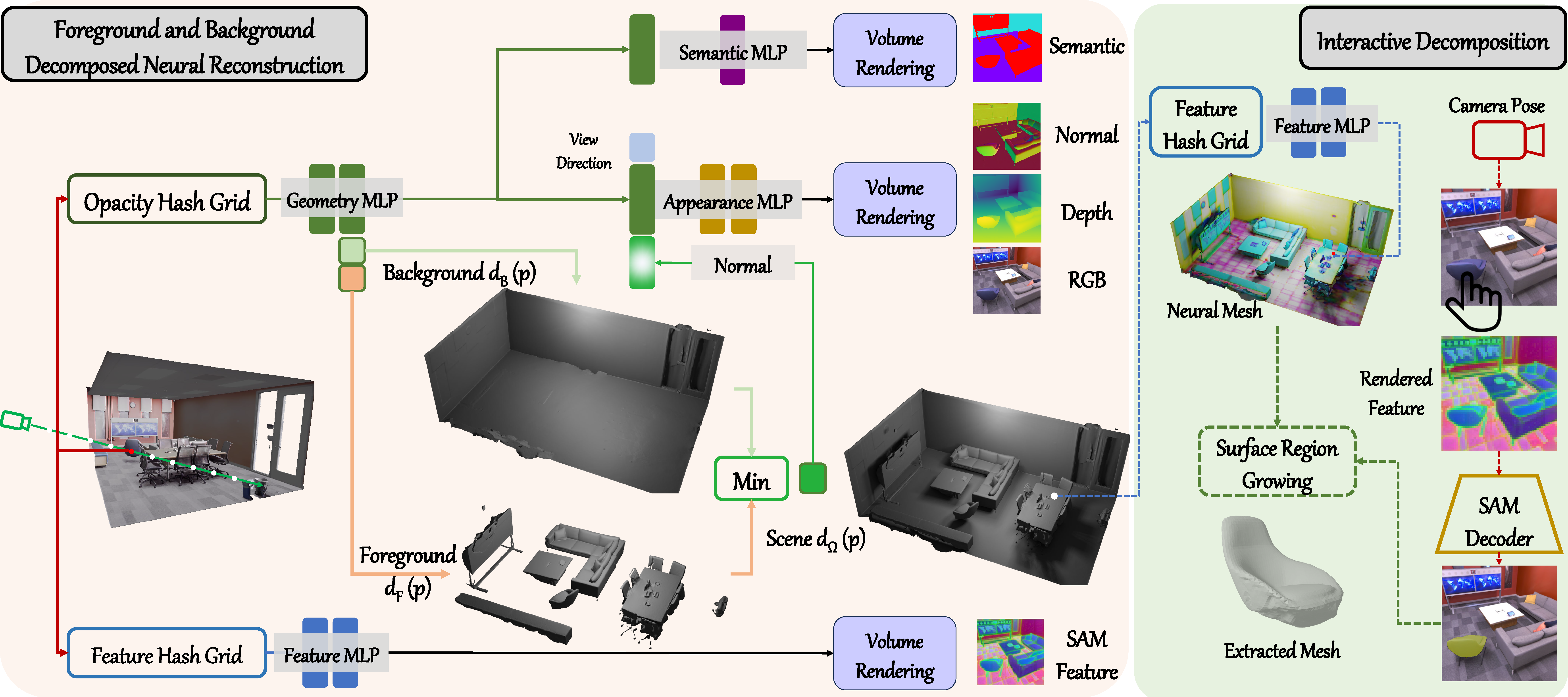
The whole pipeline for our decomposed reconstructed method. We have four networks in this stage to predict the geometry, appearance, semantic, and SAM features per point. We follow the ObjSDF++ to use the foreground and background compositional representation with pseudo geometry priors and apply min operation to construct the whole scene. Notably, the foreground is constrained with object distinct loss (Eq. (6)) and the background is regularized with Manhattan loss (Eq. (7)) and floor reflection loss (Eq. (8)). Furthermore, we also train a solely feature network to render the generalized features. (Please check the paper for more details)
Visualisation of Scene .
We have designed a graphical user interface (GUI) to interactively decompose desired objects for downstream applications. The foreground and background reconstructed meshes are loaded simultaneously, and the vertices are used as fixed initialization points to train the Gaussian Splatting model for real-time rendering. Regarding feature rendering, we utilize the trained grid and apply the rasterization method to obtain the feature map of the observed view. The rendered features and selected prompts are then passed into the SAM decoder to generate the mask for region-growing.
@article{lyu2024total,
title={Total-Decom: Decomposed 3D Scene Reconstruction with Minimal Interaction},
author={Lyu, Xiaoyang and Chang, Chirui and Dai, Peng and Sun, Yang-Tian and Qi, Xiaojuan},
journal={arXiv preprint arXiv:2403.19314},
year={2024}}